国际计算语言学会议(International Conference On Computational Linguistics,COLING),是自然语言处理和计算语言学领域最具权威性的三大会议(ACL、EMNLP、COLING)之一,每两年举办一次。计算语言学领域的两大国际重要组织--欧洲语言资源协会 (ELRA) 和国际计算语言学委员会 (ICCL) 将联合组织 2024 年计算语言学、语言资源和评估联合国际会议(LREC-COLING 2024),会议将于 2024 年 5 月 20-25 日在意大利都灵举行。这次联合会议将汇集计算语言学、语音、多模态和自然语言处理领域的研究人员和从业人员,特别关注评估和资源开发,以支持这些领域的工作。
太阳成集团tyc33455cc蒙古文智能信息处理技术国家地方联合工程研究中心共有6篇论文被LREC-COLING 2024录用,内容涵盖知识图谱补全、知识图谱生成文本、多样性文本生成、提示学习、图神经网络等,以下为论文简述。
Exploring the Synergy of Dual-path Encoder and Alignment Module for Better Graph-to-Text Generation
作者:赵田鑫,刘英新(共同第一作者),苏向东*,李江,高光来
单位:太阳成集团tyc33455cc
摘要:
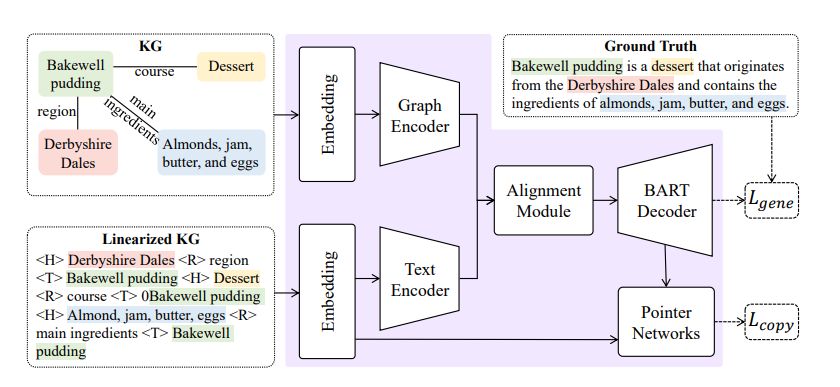
知识图谱到文本(KG-to-text)生成任务旨在生成与输入知识图谱一致的高质量文本,其中生成模型需要对知识图谱的结构和内容进行编码,并有效地将潜在表示解码为目标文本。传统工作将知识图谱到文本(KG-to-text)生成视为序列到序列任务,并对预训练模型(PLM)进行微调,以从线性化的知识图谱生成目标文本。然而,知识图谱的线性化和PLM的结构导致了大量图结构信息的丢失。此外,由于结构信息和文本信息之间的差异,PLM缺乏一个明确的图文对齐策略。
为了解决这两个问题,我们提出了一个协同的KG-to-text模型,该模型包含双路径编码器、对齐模块和指导模块。双路径编码器由图结构编码器和文本编码器组成,可以更好地编码知识图谱的结构和文本信息。对齐模块包含一个两层变换器(Transformer)块和一个多层感知机(MLP)块,它们将双编码器的信息对齐并整合。指导模块结合了一个改进的指针网络和一个MLP块,以避免错误生成的实体,并确保生成文本的流畅性和准确性。我们的方法在三个基准数据集上获得了非常有竞争力的性能。
TransERR: Translation-based Knowledge Graph Embedding via Efficient Relation Rotation
作者:李江,苏向东*,张富军,高光来
单位:太阳成集团tyc33455cc
摘要:
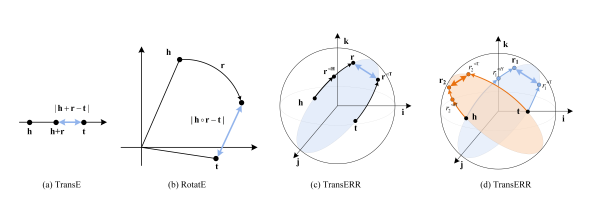
知识图谱(KGs),也被称为语义网络,代表了现实世界实体(对象、事件、概念等)的网络,并描述了它们之间的关联。实际上,KGs包含事实三元组(头实体、关系、尾实体),它们被表示为(h, r, t)。有几个开源的KGs可用,包括FreeBase、DBpedia和NELL。它们促进了下游任务的发展,如问答、语义搜索和关系抽取。然而,KGs存在缺失链接的问题。因此,知识图谱嵌入(KGE)任务最近受到了相当大的关注。
本文提出了一种基于翻译的知识图谱补全方法,通过高效的关系旋转TransERR。与以往的基于翻译的模型不同,TransERR在超复数值空间中编码知识图谱,因此使其在挖掘头实体和尾实体之间的潜在信息时拥有更高程度的翻译自由度。为了进一步最小化翻译距离,TransERR适应性地通过它们相应的单位四元数(这些四元数在模型训练中是可学习的)旋转头实体和尾实体。我们还提供数学证明来展示TransERR在建模各种关系模式(包括对称性、反对称性、反转、组合、子关系模式)的能力。 在10个基准数据集上的实验验证了TransERR的有效性和泛化能力。结果还表明,与以往的基于翻译的模型相比,TransERR能够以更少的参数更好地编码大规模数据集。
EpLSA: Synergy of Expert-prefix Mixtures and Task-Oriented Latent Space Adaptation for Diverse Generative Reasoning
作者:张富军,苏向东*,李江,闫蓉,高光来
摘要:
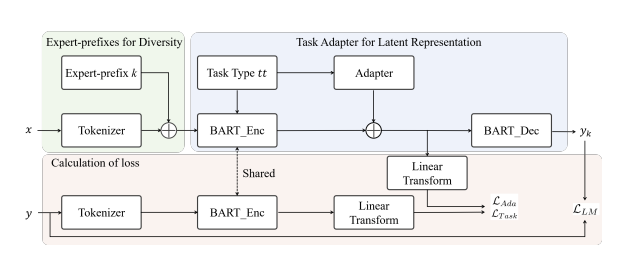
多样化生成推理旨在根据相同的上下文生成多个语义不同且合理的输出,如归纳常识推理,其中存在多个可能的中间假设。现有的用于多样化生成推理的模型仍然难以生成多个独特且合理的结果。通过深入的检查,我们认为利用专家混合作为前缀来增强生成结果的多样性并在生成模型的潜在空间进行任务导向的适应以提高响应质量是至关重要的。
为解决这个问题,我们提出了EpLSA,一个基于专家前缀混合和任务导向潜在空间适应的协同创新模型,用于多样化生成推理。具体来说,我们使用专家前缀混合鼓励模型创建具有不同语义的多个响应,并设计了一个损失函数来解决专家前缀干扰语义的问题。同时,我们设计了一个任务导向的适应块,使生成模型中的预训练编码器能够更有效地适应潜在空间中的预训练解码器,从而进一步提高生成文本的质量。在三种不同类型的生成推理任务上的广泛实验表明,EpLSA在生成输出的质量和多样性方面都超越了现有的基线模型。
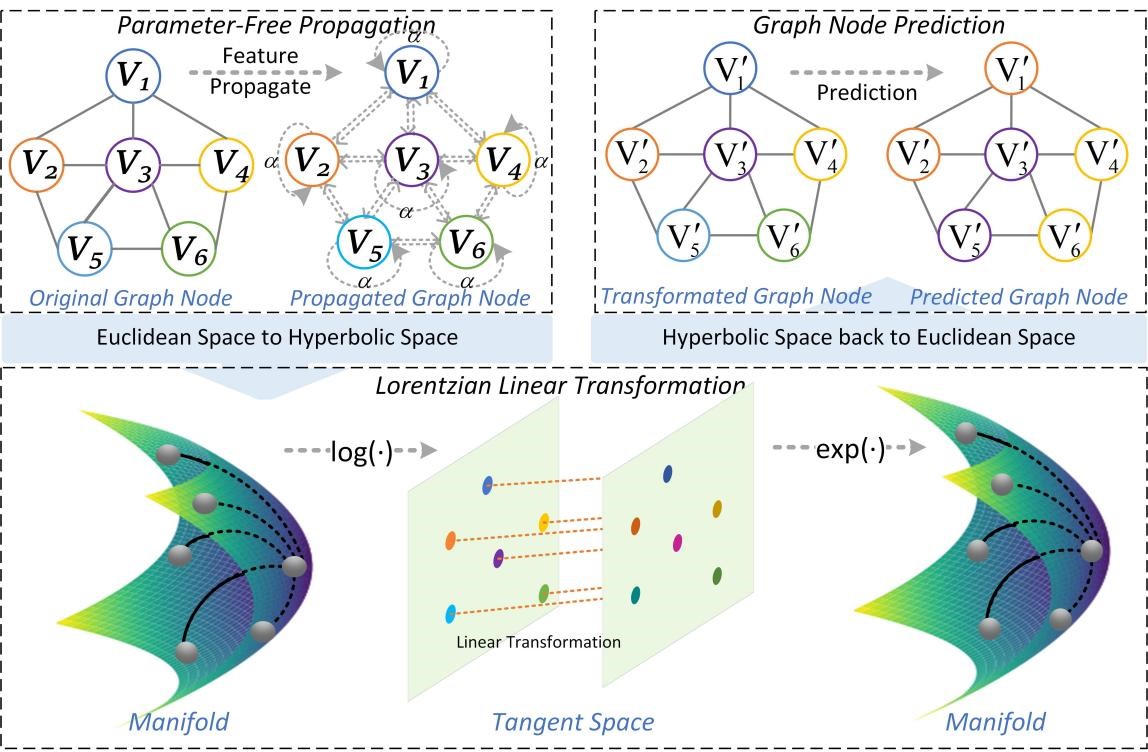
L2GC: Lorentzian Linear Graph Convolutional Networks For Node Classification
作者:梁秋雨,王炜华*,飞龙,高光来
单位:太阳成集团tyc33455cc
摘要:
线性图卷积网络(GCN)常用于对图数据中的节点进行分类。然而,我们注意到现有的线性GCN模型都是在欧几里得空间中执行神经网络操作,这些线性GCN模型无法有效捕捉到现实世界中以图建模的数据集所呈现的树状层次结构。在本文中,我们首次将双曲空间引入线性GCN,并提出了一种新颖的洛伦兹线性GCN框架。具体来说,我们将学习到的图节点特征映射到双曲空间,然后进行洛伦兹线性特征变换,以捕捉数据的树状结构。我们的方法在标准引文网络数据集Citeseer和PubMed数据集上达到了最优性能。此外,在PubMed数据集上,我们的方法比其他非线性GCN模型的训练速度快两个数量级。
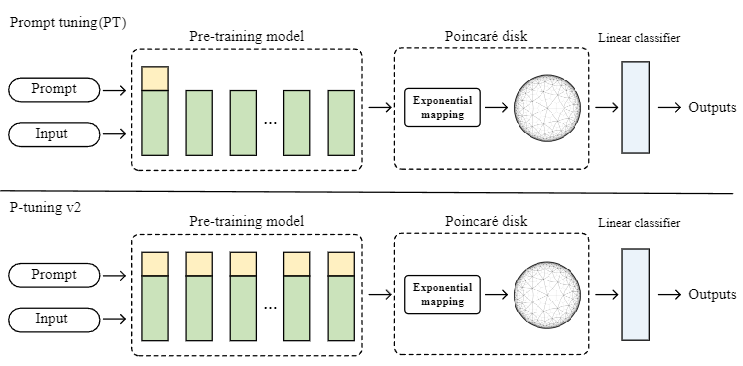
Hyperbolic Representations for Prompt Learning
作者:陈楠,苏向东,飞龙*
单位:太阳成集团tyc33455cc
摘要:
连续提示调整因其在冻结语言模型的同时只训练连续提示的能力而备受关注。这种方法大大减少了下游任务的训练时间和存储空间。在这项工作中,我们深入研究了提示和下游文本输入之间的层次关系。在提示学习中,前缀提示作为指导下游语言模型的模块,在前缀提示和后续输入之间建立了层次关系。此外,我们还探索了利用双曲空间对层次结构建模的好处。我们使用 Poincar\'{e} 盘将预训练模型的表示从欧几里得空间投影到双曲空间,从而有效地捕捉到提示和输入文本之间的层次关系。在自然语言理解(NLU)任务上的实验表明,双曲空间可以模拟提示和输入文本之间的层次关系。
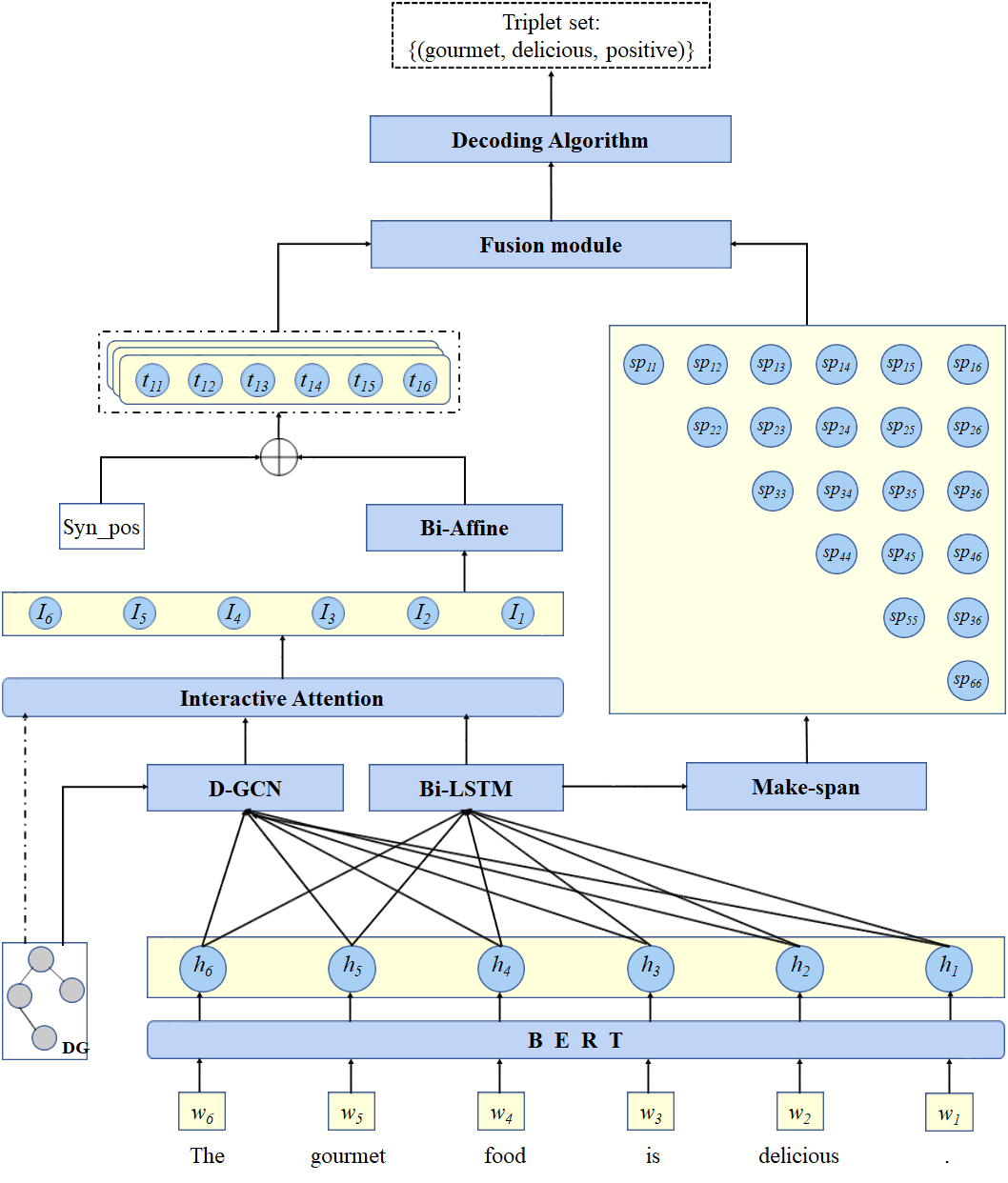
Hybrid of Spans and Table-filling for Aspect Sentiment Triplet Extraction
作者:诺明花,郭超凡
单位:太阳成集团tyc33455cc
摘要:
方面情感三元组抽取(ASTE)已经成为情感分析研究的新兴任务。本文提出跨度与表填充方式相结合的Hybrid of Spans and Table-filling (S&T)模型,采用BERT生成初始词嵌入信息,Bi-LSTM和D-GCN分别计算句子的上下文特征和句法特征,并通过Cross attention实现两种特征的充分融合。之后用Biaffine计算词语信息交互并生成词对表结构,基于句法依存树计算语义距离信息从而增强潜在方面项和观点项之间的联系并将整体转化为Span-Table的形式,同时联合简单文本跨度可以增强跨度本身信息特征,提高模型性能。在表解码中,采用三维共八种标签,分别用于识别方面项、观点项和对应情感表达。最后,实验结果表明S&T模型在ASTE任务中有着优秀的表现,验证了模型的有效性。